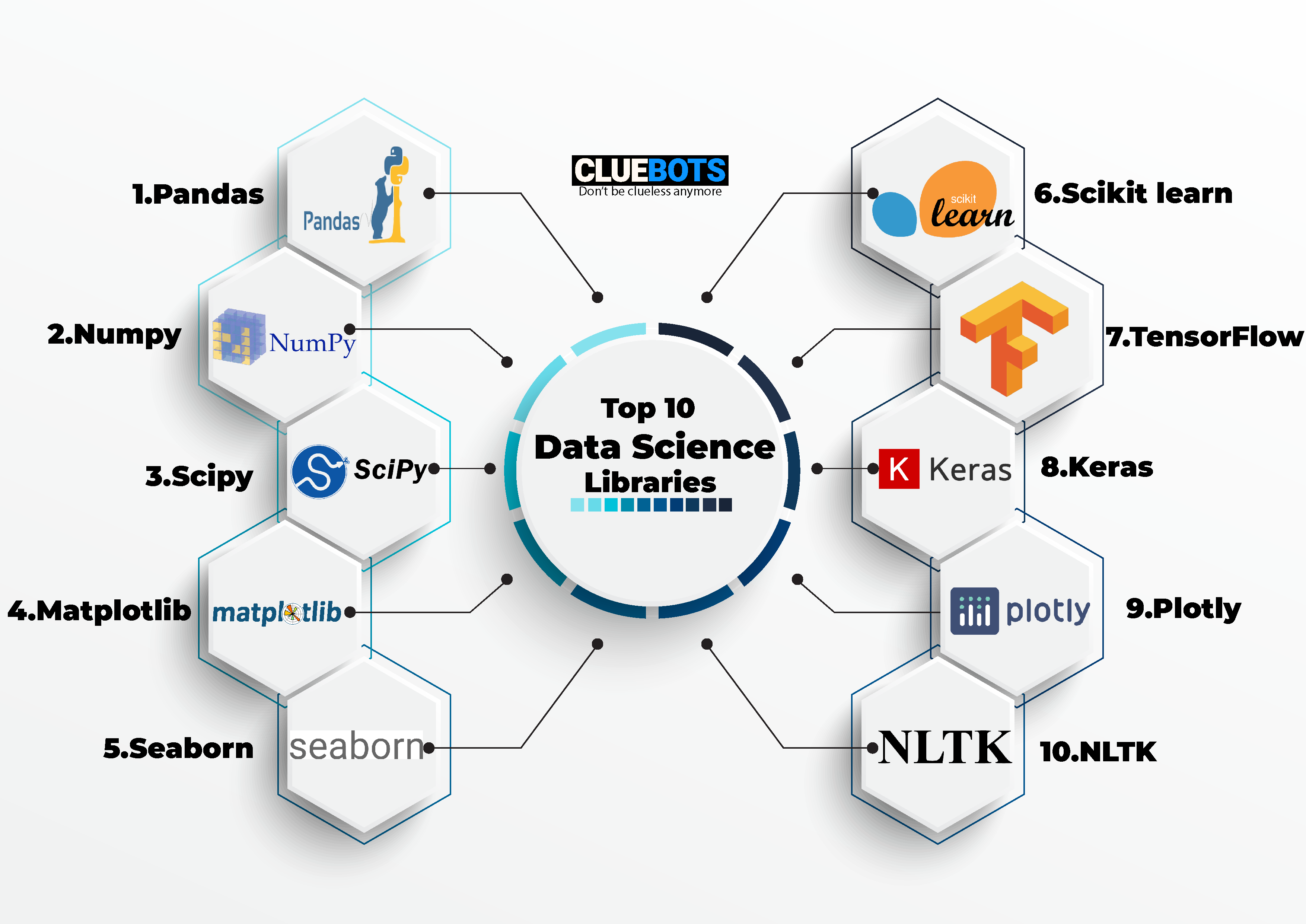
TOP 10 DATA SCIENCE LIBRARIES.
Ashish PatilPANDAS:
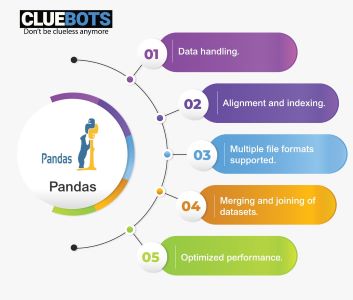
Pandas library
Pandas is a python based library that is used for data analysis and also supports multiple data structures including series and data frames which help in managing data sets and time series. It is an open source library and is one of the most commonly accepted machine learning libraries in the world.
Features:
- Pandas have an effective performance, which is why it is really fast and acceptable for machine learning.
- Pandas support accessing of different machine learning based libraries such as Numpy and Matplotlib.
- Pandas is also used to map data and supports in the generating multiple range of graphs.
- Pandas can help to merge various datasets in an efficient manner for proper analyzing of data.
- Pandas allow various data formats like JSON and CSV etc.
NUMPY:
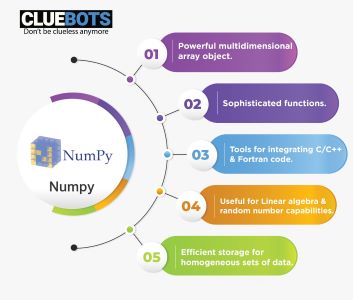
NumPy library
NumPy stands for Numerical Python, is a library which helps in scientific computing in Python. It supports high-performance multidimensional array object and multiple tools for operating with the arrays. Numpy is also used for Mathematical and logical operations to be carried out on arrays.
Features:
- Numpy performs various operations such as Linear algebra, random number capabilities and Fourier Transform.
- Numpy has open-source contribution and ample community support.
- Numpy supports multidimensional array objects and a group of routines for array management.
- Numpy is both easy to use and interactive library.
- Numpy simplifies the process of complex mathematical implementations.
SCIPY:
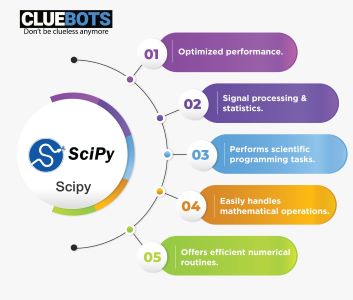
SciPy library
Scipy stands for scientific python, is a library that uses NumPy for various mathematical functions. SciPy uses NumPy arrays as the basic data structure, and are provided with components for various commonly used operations in scientific programming. All of the functions provided by the SciPy are properly recorded so it is simple to use.
Features:
- Scipy provides many efficient numerical routines like linear algebra, numerical integration and optimization using submodules.
- SciPy is the library that actually contains the numerical code and the fully-featured versions of the functions along with many others.
- Scipy has an effective performance and very simply manages mathematical operations.
- Scipy is used in signal processing and statistics and also performs various scientific programming tasks.
- Scipy is created on the Numpy extension and helps the user to handle and visualize data with different high-level commands.
MATPLOTLIB:
matplotlib library
Matplotlib is a plotting library that is used for creating static and interactive visualizations in Machine learning. Matplotlib can be used in Python scripts and web application servers etc. Matplotlib consists of several plots like line, bar, scatter and histogram etc.
Features:
- Matplotlib creates high-quality figures in multiple hardcopy formats and interchangeable environments.
- Matplotlib uses 2D plotting which allows generating bar charts, error charts, histograms, plots, scatterplots, etc. with fewer lines of code.
- Matplotlib can be placed into GUIs to create rich applications.
- Matplotlib is used to create postscript images from mathematical simulations, and still others in web application servers.
- Matplotlib has an object-oriented API for placing plots into applications using general-purpose GUI toolkits.
SEABORN:

seaborn library
Seaborn is a Python based library based on matplotlib used for data visualization. It is used for a high-level interface in drawing appealing and enlightening statistical graphics. The main purpose of Seaborn is to make visualization an important part of exploring and comprehending data.
Features:
- Seaborn provides tools for choosing colour palattes that faithfully reveal patterns in the data.
- Seaborn consists of high-level abstractions for arranging multi-plot grids which helps in simple building of complex visualizations.
- Seaborn provides support for using categorical variables to show observations or aggregate statistics.
- Seaborn provides with comfortable views of the overall structure of complex datasets.
- Seaborn provides automatic estimation and the plotting of linear regression models.
SCIKIT-LEARN:
Scikit learn library
Scikit-learn is a free machine learning library in Python that provides many unsupervised and supervised learning algorithms. It consists of many different algorithms like support vector machine, random forests, and k-neighbours. Sklearn helps in building machine learning models.
Features:
- The scikit learn library consists of many tools for machine learning and statistical modeling like classification, regression and dimensionality reduction.
- Scikit-Learn has cross-validation feature, which allows for using more than a single metric.
- Scikit learn features a range of simple-yet-efficient tools for accomplishing data analysis and mining tasks.
- Scikit learn has various methods for checking the accuracy of supervised models on unseen data.
- Scikit learn is open source and commercially usable and requires both numpy and scipy as its dependencies.
TENSORFLOW:
Tensor Flow library
TensorFlow is an open source library used in data science and machine learning. It has a inclusive, adaptable ecosystem of tools, libraries and community resources that can be used in ML powered applications. TensorFlow also helps in dataflow and differentiable programming across various tasks.
Features:
- TensorFlow is used to build and train Machine Learning models easily using intuitive high-level APIs.
- TensorFlow handles and controls data by building a dataflow graph or a Computational graph.
- TensorFlow helps in creating complicated Deep Learning models.
- TensorFlow allows training multiple neural networks and multiple GPUs, making models very efficient for large-scale systems.
- TensorFlow makes the visualizing process easier for each and every part of the graph.
KERAS:
Keras library
Keras is a high-level neural networks library which generally runs above the TensorFlow, CNTK, and Theano. It has great services for compiling models, processing datasets and visualizing graphs etc. Keras focuses on allowing fast experimentation. Keras is written in Python code which is easy to debug and allows ease for extensibility.
Features:
- Keras consists of a consistent interface optimized for common use cases which provides clear and actionable feedback for user errors.
- Keras helps in easily writing custom building blocks for innovative ideas and researches.
- Keras models are built by joining configurable building blocks together.
- Keras offers compatible & easy understandable APIs which helps in reducing the actions performed by user and gives clear and actionable feedback upon user error.
- Keras allows for easy and fast prototyping, also running seamlessly on CPU and GPU.
PLOTLY:
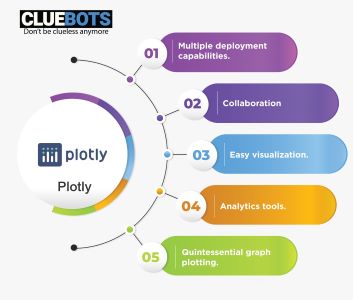
Plotly library
Plotly is a python based library that builds communal and high quality graphs. Plotly is a web-based graphing and analytics platform. Plotly helps users to copy and paste and stream data to be analyzed and visualized.
Features:
- Plotly helps in online graphing, analytics, and statistics tools for users and scientific graphing libraries.
- Plotly is a scientific graphing library and offers a sandboxed Python.
- Plotly is also used for sending data to cloud servers.
- Plotly has multiple deployment capabilities and has various tools for data analysis.
- Plotly helps in easy visualization and collaboration.
NLTK:
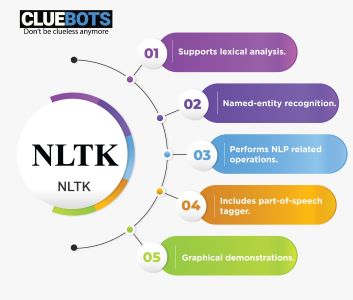
NLTK library
NLTK stands for Natural Language Toolkit, is a Python library written for working and modeling text. It consists of excellent tools for loading and cleansing operations that is performed to get the data ready for performing with machine learning algorithms. NLTK also is not at all complicated, easily understandable and simple to learn.
Features:
- NLTK consists of various libraries based on text processing for tokenization, classification, stemming, tagging and semantic reasoning.
- NLTK is helps in writing Python programs that performs tasks with human language data to put in statistical natural language processing.
- NLTK provides a platform for prototyping and creating research systems.
- NLTK consists of graphical demonstrations and sample data.
- NLTK provides lexical analysis and has part-of-speech tagger.